
The Only Two Fundamentals of Web Scraping You Need
Episode #2 of the course Build your own web scraping tool by Hartley Brody
One of the most overwhelming parts of web scraping is the sheer number of technologies and tools out there. It can make it feel like web scraping is only for elite software developers and out of reach of business owners and non-technical folks.
Fortunately, that’s not true at all.
There are really only two core web technologies that the average web scraping program deals with, and both are things you’re already doing every day:
1. Making the right HTTP requests
2. Parsing the HTML response content
Little did you know, your browser is already doing most of the heavy lifting on both of these tasks as you browse the web.
Every time you visit a new URL and see a page rendered on the screen, it’s because your browser made a request to the site’s web server and then parsed the response content it got back.
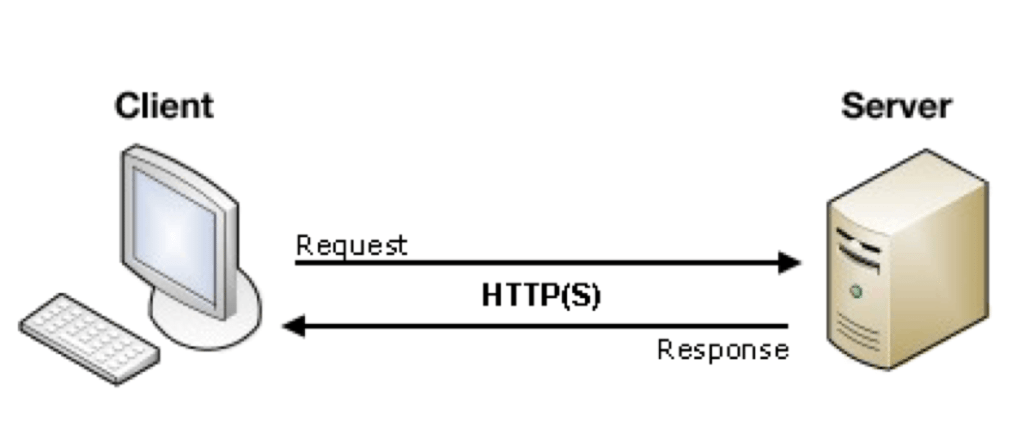
Let’s look at both of these concepts in a bit more detail.
Making HTTP Requests
“Making HTTP requests” is just a fancy way of saying “visiting a URL.” Whenever you click a link, submit a form, open a bookmark, or type a URL into your browser and hit “enter,” you’re making an HTTP request from your computer to the target site’s web server.
The majority of the HTTP request’s information is stored in the URL—things like the protocol, subdomain, domain, path, and query parameters. You’re probably used to seeing most of these things in the URLs you copy/paste around.

There are other important bits of information—like the request method, headers, and cookies—that your browser automatically sends behind the scenes.
In order to get the data we want from a website, we need to make the correct HTTP request to that site’s web server. The web server receives our HTTP request and uses that information to decide what information to return. The web server will then send an HTML response, containing all the data necessary to render the page in our browser.
Parsing HTML Responses
Once you’ve made an HTTP request, the response you get back 99.9% of the time is a simple HTML document. HTML is a simple markup language that’s used to build every website you visit.
If you right click on any page in your browser and choose “view source,” you can see the raw HTML response that came back from the server in response to your HTTP request to that page’s URL. Your browser is tasked with taking all that data and turning it into the beautiful, structured web pages you’re used to visiting.
If there’s a specific bit of text on the page you’re hoping to extract, try searching for it (with cmd+F or ctrl+F) in all of that HTML tag soup. Hopefully, you’ll find the data you’re looking for—then you can start looking for patterns in the HTML tags around it.
If the data you’re hoping to extract isn’t in the HTML, don’t panic. In a future lesson, we’ll cover how to scrape sites that don’t return the data immediately in the response. For now, just spend some time visiting a few different websites, opening the “view source” window, and trying to find the bits of data you saw on the page, tucked into all the raw HTML tags.
It’s important to understand these concepts in detail, because building our own web scraper is essentially like building our own mini web browser. We want to make a program that sends the right HTTP requests and then parses the HTML response to extract the data we’re hoping to scrape. Rather than rendering the response HTML into a web page, we’ll pull out the bits we need for our program.
In our next lesson, we’ll look at a few free tools the browser provides that makes this discovery process a bit easier.
Recommended book
HTML and CSS: Design and Build Websites by Jon Duckett
Share with friends