
Spot the Inference
Episode #5 of the course An introduction to data science by Roger Peng
In this lesson, you’ll learn about using data to make an inference about a larger population.
Inference is one of many possible goals in data analysis, so it’s worth discussing what exactly is the act of making inference. Recall previously that we described one of the six types of questions you can ask in a data analysis as an inferential question. So what is inference?
In general, the goal of inference is to be able to make a statement about something that is not observed, and ideally to be able to characterize any uncertainty you have about that statement. Inference is difficult because of the difference between what you are able to observe and what you ultimately want to know.
Consider this group of penguins below (because penguins are awesome), each wearing either a purple or turquoise hat. There are a total of ten penguins in this group. We’ll call them the population.
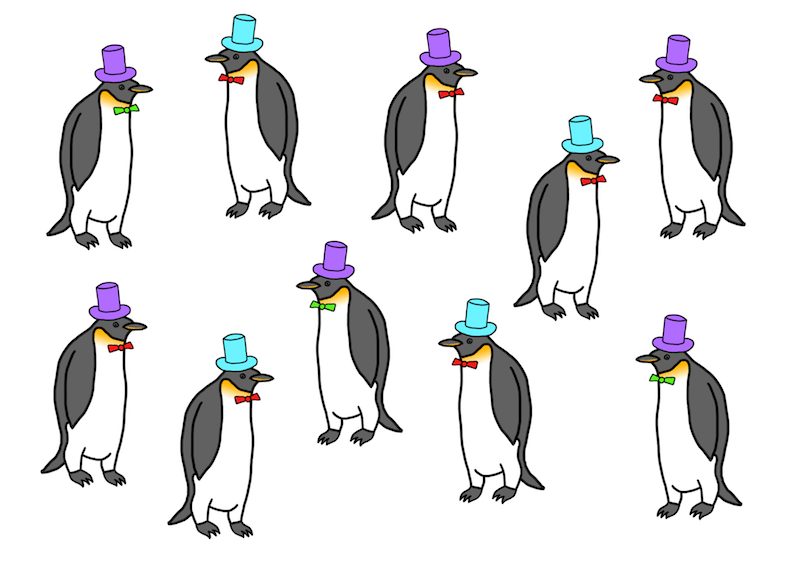
Population of Penguins with Turquoise and Purple Hats
Now suppose you wanted to know what proportion of the population of penguins wears turquoise hats. But there’s a catch—you don’t have the time, money, or ability to take care of ten penguins. Who does? You can only afford to take care of three penguins, so you randomly sample three of these ten penguins.
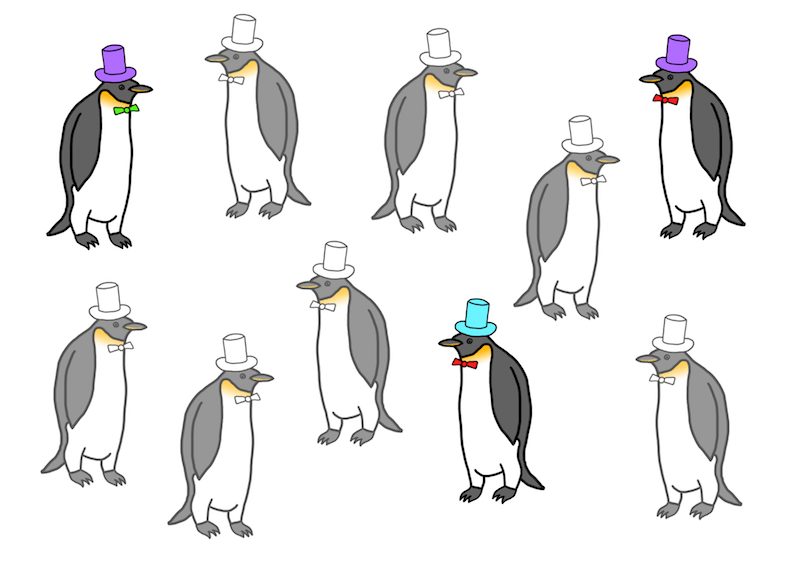
Sample of Three Penguins from Population
The key point is that you never observe the full population of penguins. Now what you end up with is your dataset, which contains only three penguins.

Dataset of Penguins
At this point an easy question to ask is, “What proportion of the penguins in my dataset are wearing turquoise hats?” From the picture above, it’s clear that 1/3 of the penguins are wearing turquoise hats. We have no uncertainty about that proportion because the data are sitting right in front of us.
The hard question to ask is “Based on the data I have, what proportion of the penguins in the original population are wearing turquoise hats?” At this point, we just have our sample of three penguins and do not observe the full population. What can we do? We need to make an inference about the population using the data we have on hand. The three things that we need to do to make an inference are:
1. Define the population. Here, the population is the original ten penguins from which we sampled our dataset of three penguins.
2. Describe the sampling process. We haven’t explicitly mentioned this, but suppose for now that our “sampling process” consisted of taking the first three penguins that walked up to us.
3. Describe a model for the population. We will assume that the hats the penguins wear are independent of each other, so the fact that one penguin has a purple hat doesn’t influence whether another penguin has a turquoise hat. Since we only want to estimate a simple proportion of penguins with turquoise hats, we don’t need to make any more complex assumptions about how penguins relate to each other.
Given the three ingredients above, we might estimate the proportion of penguins with turquoise hats to be 1/3. How good of an estimate is this? Given that we know the truth here—that 2/5 of the penguins have turquoise hats in the population—we might ask whether 1/3 is a reasonable estimate or not.
In this lesson, I’ve presented the three key questions you need to think about when doing inference: What is the population? What is the sampling process? What is the model? Knowing the answers to these questions will allow you to evaluate the quality of the conclusions you draw from the data.
Tomorrow, you’ll learn about using models to analyze your data.
Recommended book
“Naked Statistics: Stripping the Dread from the Data” by Charles Wheelan
Share with friends