
K-Nearest Neighbor
Episode #1 of the course Business analysis fundamentals by Polina Durneva
Hi, my name is Polina, and I’m a business analyst. In this course, I’ll introduce you to a variety of methods commonly used in predictive analytics, data mining, and managerial science. While most of us have heard how “hot” big data is becoming nowadays, few of us understand what actually stands behind big data.
In ten days, we’ll cover different data-driven and model-based approaches that modern companies are actively using, and we’ll discuss the most popular applications of these approaches not only in business but also in other fields.
Let’s start with the K-Nearest Neighbor algorithm, which can be used for both prediction and classification.
What Is the K-Nearest Neighbor Algorithm?
The K-Nearest Neighbor algorithm (KNN) is probably one of the simplest methods currently used in business analytics. It’s based on classifying a new record to a certain category by finding similarities between the new record and the existing records.
To better understand the idea behind this algorithm, let’s imagine that you have a child who is applying to college this year. Your child recently submitted their SAT scores and academic transcript to College A and College B. Trying to cope with college admission anxiety, you decide to evaluate where your child fits better. Let’s look at the chart below.
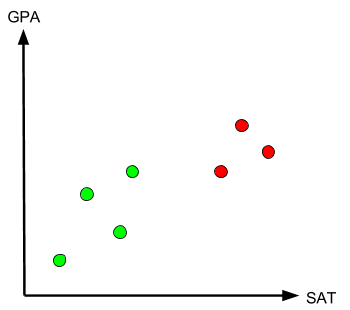
The chart contains the GPAs and SATs of seven people that (you can confirm) were admitted to either College A or B. The green dots stand for people admitted to College A, and the red dots stand for people admitted to College B. You can see from the graph that College B tends to admit students with higher SAT scores and GPAs than College A.
Now, let’s put another point on this graph to evaluate your child’s academic potential based on their SAT and GPA.
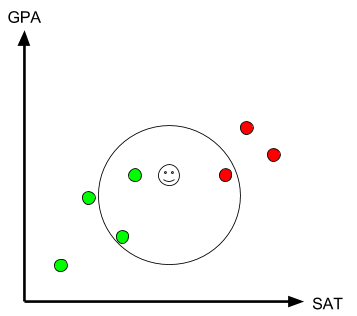
Here is the main and most important idea in KNN. We will look at the number k (the number of neighbors) to classify the new record (your child). Let’s assume k=3 (how k is chosen will be discussed in the next section). If k=3, we will look at the three nearest neighbors of your child. In the chart, the three nearest neighbors (the ones located closer to your child than anyone else) are two green dots and one red dot, suggesting that your child will probably fit better in College A. However, if we look at k=6, we will see that there will be three green and three red dots, suggesting that your child can fit in either of the two colleges.
How Many Neighbors (k) Should We Choose?
While KNN is a relatively easy concept, the biggest challenge here is to decide on the number k. As we have seen in the above section, different k’s lead to different conclusions.
Usually, when we have a big dataset, a small value of k might distort our analysis: We might capture a lot of noisy data and miss the main point. On the other hand, if k is too high, we are not taking advantage of the KNN algorithm, since its main purpose is to focus on the nearest neighbors.
Ideally, we would try to avoid even k’s: In the previous section, it was shown that even k’s may lead to the equal split between two categories, College A and College B.
There actually exists a number of ways to determine k, and in most cases, the complexity and irregularity of data can be evaluated to determine the number of neighbors. In our very simple example, a k of 3 and a k of 5 will lead to the same result, and therefore, we might just use one of these values.
Most Famous Modern Applications
Here are the most famous examples of the application of KNN algorithm:
• Stock prediction. Stock price can be evaluated using different parameters and KNN.
• Face recognition. Yes, the KNN algorithm can be applied to build face recognition systems. The process is very complicated but is based on KNN.
• Credit card usage. KNN can be used to detect some suspicious activities.
That’s it for today. Tomorrow, we will talk about another business analytics method: the Naïve Bayes classifier.
See you soon,
Polina
Recommended book
A Guide to the Business Analysis Body of Knowledge by International Institute of Business Analysis
Share with friends