Trees
Episode #9 of the course Kurt Anderson by Computer science fundamentals
Welcome back!
Trees are some of the most used data structures in computer science. They link information together in a relational way. You can use them to sort information, store information, make inferences, and so much more. They are even used in databases to help index (find) the data.
Parents and Children
Trees are known as a hierarchical data structure. Instead of pointing from one piece of data to the next, a tree has many different paths that you can take from each node. This creates a system of parents and children.
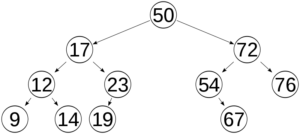
Parents are the nodes that are directly above another node, while children are ones that are directly below. For example, node 23 is a child of node 17, and node 17 is therefore the parent of node 23. However, the relationship is only a direct relationship. So, node 67 is not a child of node 23, and 19 is not a child of 17. They are “descendants,” as they are lower in the tree, but not children.
You also have nodes called leaves. These are the nodes without any children, meaning they are at the end of the tree structure. Once you reach them, you cannot go any further in the tree.
Levels
The levels of the tree are also important. They are known as the height of tree. This is important in many mathematical operations. Remember mergesort and quicksort? The reason they have nlogn is because the divide-and-conquer methodology creates a tree.
The number of comparisons in these algorithms are related to the height of the tree. Mathematically, the height of the tree comes out to logn. So, these algorithms run n number of comparisons, logn times, which creates the nlogn relationship.
Trees are also typically one directional, so you go from parent, to child, to child, to child, etc. You don’t typically go back up the tree for any purpose, except maybe a printing of a tree.
Binary Search Tree
A binary search tree is a tree with these rules:
• Each node can only have at most two children.
• All right children must be greater than their parent.
• All left children must be less than or equal to their parent.
Through these rules, we create a tree that can actually be used to search for things. Because we know the above rules, we can actually traverse the tree to find a number. The picture you saw above is a binary search tree.
Let’s see if 19 is in this tree. We take the root node (the one at the very top) 50, and ask, is 19 greater or less than this node of 50? It’s less. So, we look at the left child. 50->17. We then ask the same question: Is 19 greater or less than 17? It’s greater, so we take the right child. 50->17->23. Now is 19 greater or less than 23? It’s less than. We take the left child, and there we have it, the number is in the tree.
If the number were, for example, 22, we would do the same procedure and find out that when we tried to look at the right child of 23, there is nothing there. We would then return that, no, 22 is not in the tree. So with this ability to search the tree with only touching a few elements, we get great time efficiencies.
(This assumes random order of inserting. If you insert a series of consecutive numbers, you will grow the tree in a straight line, making all operations the same as a list, so O(n). There are more advanced trees, known as red-black trees and AVL trees, that make sure this never happens. But they are quite complex and out of the scope of this course.)
Search: O(log n) – We only have to touch log elements (the height of the tree) to figure out if the element is in the list or not.
Insert: O(log n) – This is same with inserting into the tree. We ask the same questions as above and find the empty place in the tree and insert there.
Delete: O(log n) – The same as the rest, we can delete by just asking the same questions.
Key takeaways:
• Trees create a height-based relationship between nodes.
• Trees can have certain structures that give them the ability to sort or access data really fast.
• The height of a tree is on average log(n), with n being how many elements are in the tree.
Tomorrow, we will tie everything we have learned together.
Cheers,
Kurt
Recommended resources
Binary Tree | Set 1 (Introduction): More explanation on BSTs.
Binary Search Tree | Set 1 (Search and Insertion): More explanation on search and insertion with BSTs.
Data Structure—Binary Search Tree: Seeing how a BST might be implemented in code.
AVL Trees: A self-balancing tree (if you are feeling adventurous).
Share with friends